介绍
分片上传
分片上传就是将所要上传的文件,按照一定的大小,将整个文件分隔成多个数据块(我们称之为 Part)来进行分别上传,上传完之后再由服务端对所有上传的文件进行汇总整合成原始的文件。
小文件(图片、文档、视频)上传可以直接使用很多 ui 框架封装的上传组件,或者自己写一个 input 上传,利用 FormData 对象提交文件数据,后端使用 Spring 提供的 MultipartFile 进行文件的接收,然后写入即可。但是对于比较大的文件,比如上传2G左右的文件(http上传),就需要将文件分片上传(借助于 file.slice() ),否则中间 http 长时间连接可能会断掉。
断点续传
断点续传是在下载或上传时,将下载或上传任务(一个文件或一个压缩包)人为的划分为几个部分,每一个部分采用一个线程进行上传或下载,如果碰到网络故障,可以从已经上传或下载的部分开始继续上传或者下载未完成的部分,而没有必要从头开始上传或者下载。
断点续传可以看成是分片上传的一个衍生,因此可以使用分片上传的场景,都可以使用断点续传。
核心逻辑
在分片上传的过程中,如果因为系统崩溃或者网络中断等异常因素导致上传中断,这时候客户端需要记录上传的进度。在之后支持再次上传时,可以继续从上次上传中断的地方进行继续上传。
为了避免客户端在上传之后的进度数据被删除而导致重新开始从头上传的问题,服务端也可以提供相应的接口便于客户端对已经上传的分片数据进行查询,从而使客户端知道已经上传的分片数据,从而从下一个分片数据开始继续上传。
整体过程
前端将文件按照百分比进行计算,每次按照百分比上传文件(文件分片,指定分片大小),给文件分片做上序号
后端将前端每次上传的文件,放入到缓存目录
等待前端将全部的文件内容都上传完毕后,发送一个合并请求(后端自行判断也可)
后端使用
RandomAccessFile进多线程读取所有的分片文件,一个线程一个分片后端每个线程按照序号将分片的文件写入到目标文件中
在上传文件的过程中发生断网了或者被手动暂停了,下次上传的时候发送续传请求,让后端删除最后一个分片
前端重新发送上次的文件分片
最后上传缺少的分片即可
秒传
秒传通俗地说,你把要上传的东西上传,服务器会先做MD5校验,如果服务器上有一样的东西,它就直接给你个新地址,其实你下载的都是服务器上的同一个文件,想要不秒传,其实只要让MD5改变,就是对文件本身做一下修改(改名字不行),例如一个文本文件,你多加几个字,MD5就变了,就不会秒传了。
参数设计
| 字段名 | 类型 | 释义 |
|---|---|---|
| chunkNumber | Integer | 当前块的次序,第一个块是 1,注意不是从 0 开始的 |
| totalChunks | Integer | 文件被分成块的总数 |
| chunkSize | Long | 分块大小,根据 totalSize 和这个值就可以计算出总共的块数。 注意最后一块的大小可能会比这个要大 |
| currentChunkSize | Long | 当前块的大小,实际大小 |
| totalSize | Long | 文件总大小 |
| identifier | String | 这个就是每个文件的唯一标示 |
| filename | Sting | 文件名 |
| relativePath | String | 文件夹上传的时候文件的相对路径属性 |
| file | MultipartFile | 文件块 |
流程设计
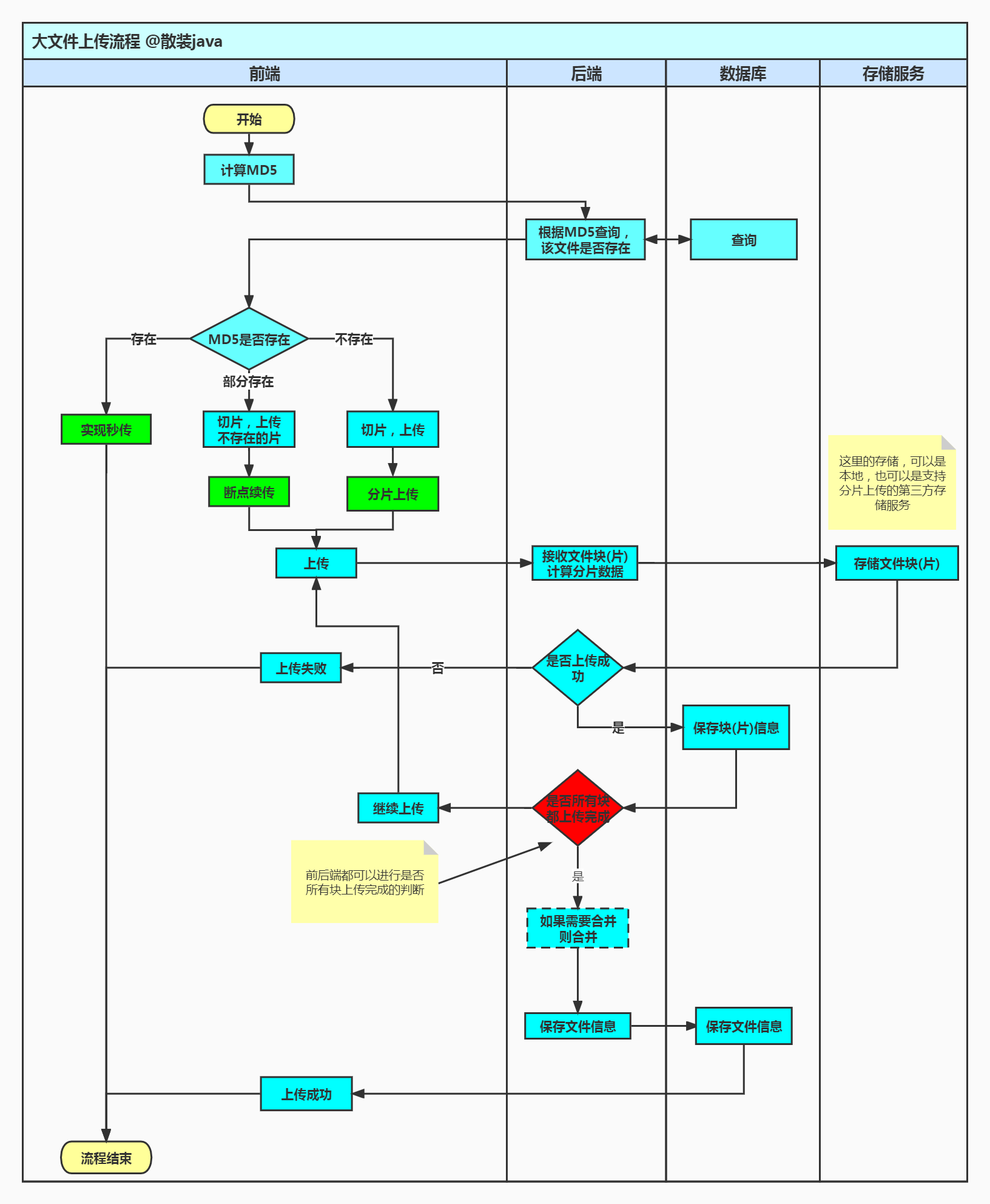
校验
前端首先计算文件 md5 值,在上传文件前调用接口查询服务器是否存在该文件,如果不存在,直接按业务准备接下来的文件上传;如果存在则跳过该文件的上传并返回可访问的文件 url,以此实现秒传效果;部分存在,需要查找已经上传过的分片,有多种方案可选,这时前端再根据该集合上传未上传的分片即可。
文件的分片上传记录如果使用磁盘存储,可以通过表查询已经上传的分片数
分片上传通常也可以使用
Redis来记录,以此来返回需要上传的分片集合读取
.conf文件内容,创建的conf文件长度为总分片数,每上传一个分块即向conf文件中写入一个127,那么没上传的位置就是默认的 0,已上传的就是1271
2
3
4
5
6
7
8List<Integer> uploadedChunks = new LinkedList<>();
byte[] completeStatusList = Files.readAllBytes(confFile.toPath());
for (int i = 0; i < completeStatusList.length; i++) {
if (completeStatusList[i] == Byte.MAX_VALUE) {
uploadedChunks.add(i);
}
}上传的文件分片保存时可以通过规律数字命名的方式,通过检查分片是否存在也可得到
上传
开始执行文件上传,后端用两种方式实现文件写入
RandomAccessFile
Java 除了 File 类之外,还提供了专门处理文件的类,即 RandomAccessFile(随机访问文件)类。
该类是 Java 语言中功能最为丰富的文件访问类,它提供了众多的文件访问方法。RandomAccessFile 类支持“随机访问”方式,这里“随机”是指可以跳转到文件的任意位置处读写数据。在访问一个文件的时候,不必把文件从头读到尾,而是希望像访问一个数据库一样“随心所欲”地访问一个文件的某个部分,这时使用 RandomAccessFile 类就是最佳选择。
RandomAccessFile 对象类有个位置指示器(文件指针),指向当前读写处的位置,当前读写 n 个字节后,文件指示器将指向这 n 个字节后面的下一个字节处。我们可以通过 RandomAccessFile 的 seek(long pos) 方法来设置文件指针的偏移量(距文件开头 pos 个字节处)。如果想要获取文件指针当前的位置的话,可以使用 getFilePointer() 方法。
刚打开文件时,文件指示器指向文件的开头处,可以移动文件指示器到新的位置,随后的读写操作将从新的位置开始。
RandomAccessFile 类在数据等长记录格式文件的随机(相对顺序而言)读取时有很大的优势,但该类仅限于操作文件,不能访问其他的 I/O 设备,如网络、内存映像等。
RandomAccessFile 类的构造方法
1 | // 创建随机存储文件流,文件属性由参数File对象指定 |
这两个构造方法均涉及到一个 String 类型的参数 mode,它决定随机存储文件流的操作模式,其中 mode 值及对应的含义如下:
r:以只读的方式打开,调用该对象的任何 write(写)方法都会导致 IOException 异常rw:以读、写方式打开,支持文件的读取或写入。若文件不存在,则创建之。rws:以读、写方式打开,与rw不同的是,还要对文件内容的每次更新都同步更新到潜在的存储设备中去。这里的s表示synchronous(同步)的意思rwd:以读、写方式打开,与rw不同的是,还要对文件内容的每次更新都同步更新到潜在的存储设备中去。使用rwd模式仅要求将文件的内容更新到存储设备中,而使用rws模式除了更新文件的内容,还要更新文件的元数据(metadata),因此至少要求1次低级别的 I/O 操作
保存文件分片代码实现
1 | // try 自动资源管理 |
MappedByteBuffer
java io 操作中通常采用 BufferedReader,BufferedInputStream 等带缓冲的 IO 类处理大文件,不过 java nio 中引入了一种基于 MappedByteBuffer 操作大文件的方式,其读写性能极高,想要深入了解的话可以读一下《深入浅出MappedByteBuffer》
如果用的是第三方存储,那么只要调用第三方提供的分片上传 api 即可
记录分块位置
服务端创建 .conf 文件用来记录分块位置,.conf 文件长度为总分片数,每上传一个分块即向 .conf 文件中写入一个 127,那么没上传的位置就是默认的 0,已上传的就是 Byte.MAX_VALUE 127
服务器按照请求数据中给的分片序号和每片分块大小(分片大小是固定且一样的)算出开始位置,与读取到的文件片段数据,写入文件。
1 | /** |
分片全部上传完成
其实之前的分片一边上传,一边已经做到了文件合并 (每次调用上传接口其实读写的都是同一个 tmp 文件),所以这时的 tmp 文件其实就是完整的原文件,仅仅文件名不同,我们可以多校验一下 md5 值,确保文件没有损坏,确认过后将 tmp 文件重命名即可,至此文件上传全部完成
1 | /** |
还有一种处理方案,上传接口每次保存的都是一份 tmp 文件,当分片全部上传完成后需要执行合并分片,这里给出伪代码
1 | /** |
项目运行
简单实现:MyGitee
为了方便演示使用,本项目使用的是前后端不分离的架构
- 确认文件上传路径 默认是
F:\tmp可在application.yml中进行修改 - 连接自己的数据库,导入
sql目录下面的db.sql(注意application.yml中的数据库名,用户名密码) - 分片大小,前后端要对应相同才行(默认是相同的20M不用改)
BigfileUploadApplication是启动类,直接启动即可- 启动后访问:http://localhost:8080/page/index.html